
(前回の続き)
ちなみに前回のケースは、条件部分に書かれている
契約( $id_no : 証券番号, 基本保険金額 > 30000000)
は、制約条件が「基本保険金額 > 30000000」の一つですが、これにたとえば「○○特約付加==true」などという条件が加わると、ネットワーク上は、「基本保険金額 > 30000000」のαノードの次に、「○○特約付加==true」のαノードが直列に付け加わります。
さて次にβノードを用いた実例を見てみましょう。αノードは一つのファクトに対する制約条件でしたが、βノードは複数のファクトにまたがる制約条件を表すノードとなります。このノードは2つの入力(Left Input, Right Input)があり、左の入力はファクトの組、右の入力は、ファクトとなります。またこのそれぞれの入力は、部分的にマッチしたファクトの組やファクトの待機場所となるメモリを持ちます。
ここでは典型的なβノードであるJoinノードを例にとって見てみましょう。
先ほどのルールに加えて、もう一つルールを加えてみます。
| package com.sample declare 契約 declare 顧客 rule “基本保険金額1” rule “基本保険金額2” |
新たに加えた、基本保険金額2のルールは、顧客タイプのファクトに対する条件を加えています。顧客が持っている保険契約(リスト)に基本保険金額が3000万を超えるものがあればメッセージを出力するというものです。
このルールファイルは以下の形のReteネットワークとなります。
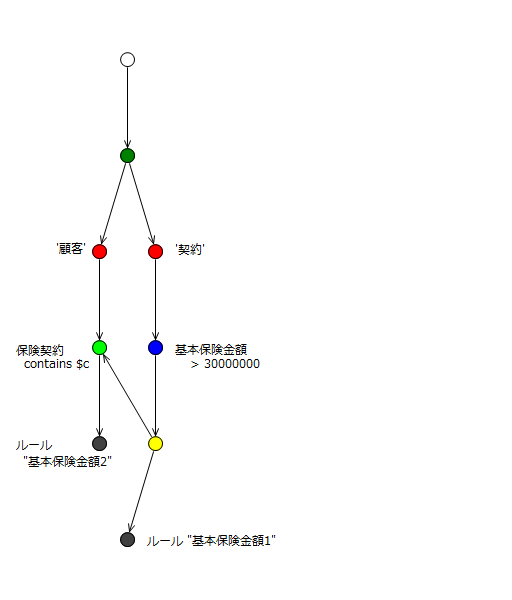
まず、同じ条件の部分は、2つのルールでグラフのノードが共有されていることに注意ください。さらに新たな種類のノード(黄緑のノード)が表れています。これがβノードの一種であるJoin ノードになります。
- Joinノード
LeftInputAdapterノードから入ってくるファクトの組(Left Input)と、Right Input
からのファクトとを合わせて判断し、条件が満たされれば入力から新たなファクトの
組をつくり、次に渡す。
では、上記のネットワークにファクトをinsertしてみましょう。以下のファクトを次々に加えていきます。
f-1.契約(証券番号=’10001′, 基本保険金額=40000000)
f-2.契約(証券番号=’10005′, 基本保険金額=20000000)
f-3.顧客(顧客番号=’10005′, 保険契約={f-1,f-2})
まずf-1をinsertします。契約→αノード(基本保険金額>3000万)を通過してLeftInputAdapterノードに入ります。ここでファクトの組(f-1)が生成され、2つの方向に伝播していきます。一方はTerminalノードに行き、ルール”基本保険金額1″と合わさって、実行候補のリストに付け加えられます。もう一方は、黄緑のJoinノードの左入力となります(上の図ではJoinノードの右になっていますが^^;)。
さて、Joinノードの左(上図では右)入力に(f-1)が入ってきました。Joinノードは片方の入力に値が入ってきたので、もう片方の入力のメモリを見に行きます。しかしまだメモリは空なので(f-1)はそのまま左入力のメモリに保存されます。
次にf-2をinsertしましょう。契約→αノード(基本保険金額>3000万)と行きますが、この時点でこのαノードを通過できません。
最後にf-3をinsertしましょう。顧客のファクトなので、顧客に進み、次のJoinノードの入力になります。Joinノードでは、片方の入力としてf-3が入ってきたので、f-3を右入力のメモリに保持すると同時に、左入力のメモリを見に行きます。左入力のメモリには(f-1)が入っていたので、f-3と、(f-1)を使って条件判断をします。f-3には、f-1の保険契約が含まれているので、条件が満たされ新たなファクトの組((f-1),f-3)を生成して次に渡します。最後にこのファクトの組はルール”基本保険金額2″と合わさって、実行候補のリストに加えられます。
以上、このようにしてファクトがinsertされていきます。ファクトが削除(retract)されるときは対象のファクトを入口から流して逆に削除していき、ファクトの更新の場合はretract&insertの動きになります。
以上がReteアルゴリズムの概略です。わかりにくい部分も多々あったかと思いますが、雰囲気はおおよそつかめていただけたのではないかと。
ルールベースのアプリケーションのパフォーマンス見積もりなどでは、簡単なのでついついルール数で概算見積もりをしてしまいます。しかし本来は、パフォーマンスとルール数自身とは直接の関係はありません。パフォーマンスに影響するのは、むしろルールの条件部分のバリエーションの数であるということがおわかりいただけたのではないかと思います。
あと、最近のルールエンジンの使い方から考えると、Reteアルゴリズムは少々オーバースペックなので、使い方に制限があるかわりに、より軽い Sequential アルゴリズムもよく使われますが、それはまたの機会に。
(参考文献)
Michal Bali, Drools JBoss Rules 5.0 Developer’s Guide PACKT publishing.
Jérôme Boyer, Hafedh Mili, Agile Business Rule Development Process, Architecure, and JRules Examples Springer.

コメント